
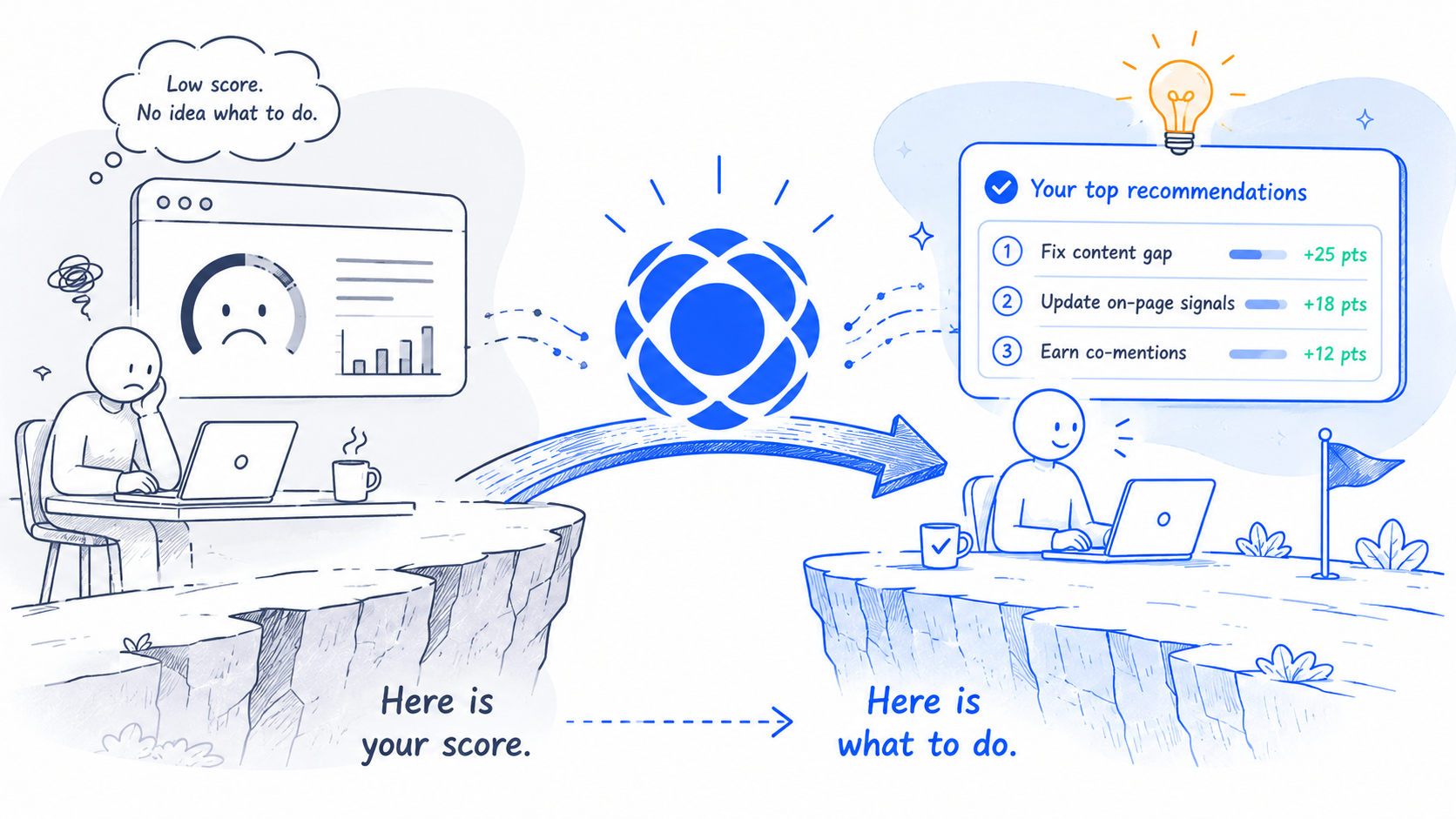
Most AI visibility tools are very good at one thing: telling you that your brand does not show up in AI answers. You log in, you see a sad-looking score, you stare at it for a minute, and then you close the tab. The data is correct. It just is not actionable.
That gap between "here is your score" and "here is what to do on Tuesday morning" is the gap our recommendations engine was built to close. It reads everything your scans surface, ranks the most impactful moves, and writes you a small punch list you can actually work through. This post walks through what it does, how to use it, and how the visibility points you can earn from each suggestion are estimated under the hood.
Why a dashboard is not enough
The space between traditional search and AI search has gotten wider, fast. Recent research from 5W tracking citation behavior across the major AI engines found that the overlap between Google's top 10 organic results and the URLs cited inside AI-generated answers has collapsed from around 70% to under 20%[^1]. Translation: where your brand ranks on Google does not reliably tell you where it shows up in ChatGPT, Perplexity, Gemini, or Google AI Overviews.
You can know that perfectly well and still not know what to do about it. The "what to do" is its own problem, and it is the one most AI visibility tools quietly avoid. A weekly visibility score is interesting. A weekly visibility score paired with a ranked list of pages to fix, schemas to add, and queries you should be writing about is a workflow.
For the wider context on why AI search needs its own optimization layer, our piece on why SEO alone is not enough in the age of AI search covers the structural shift in more depth.
What the engine actually does
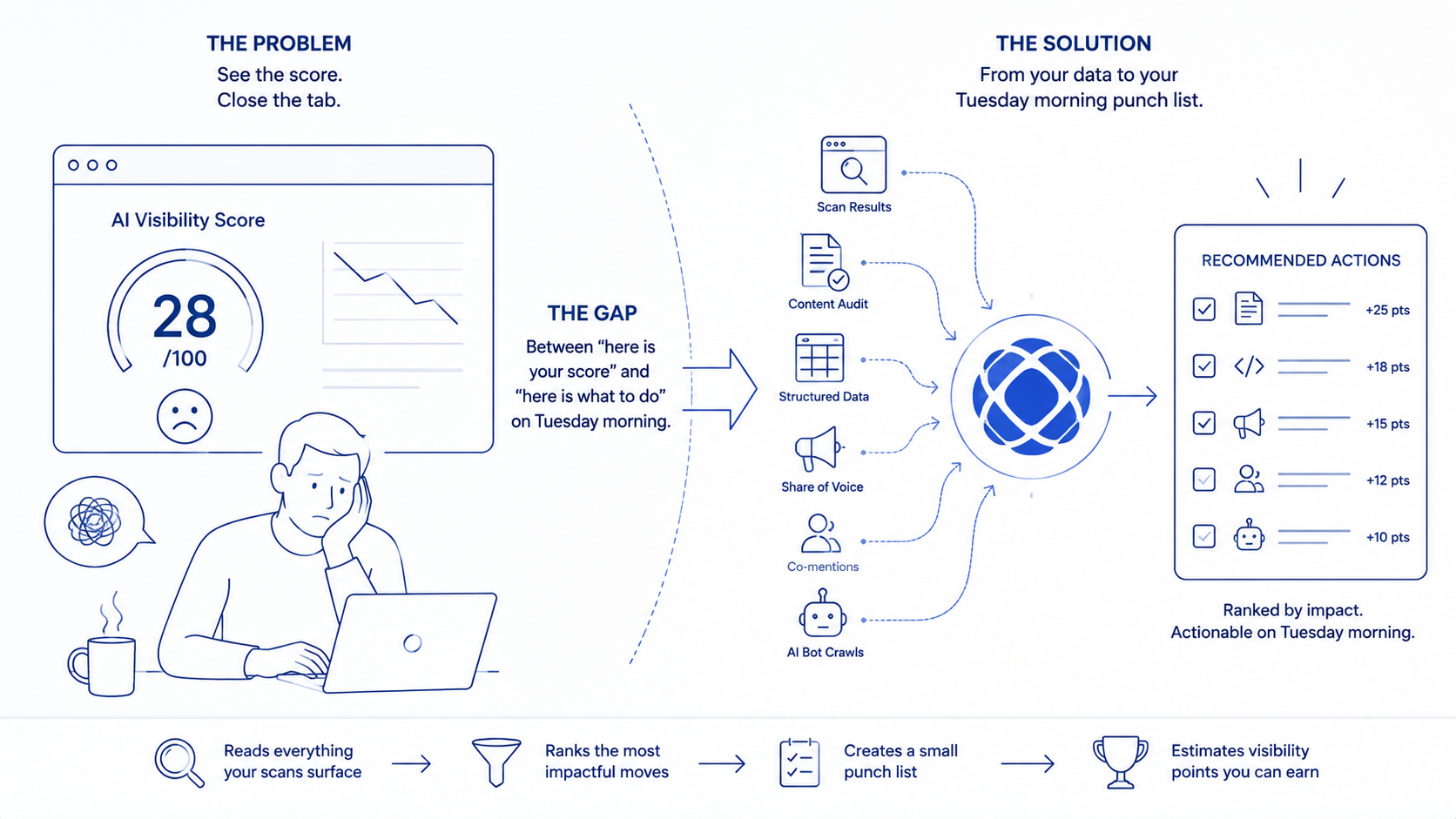
Every time your brand finishes a scan cycle, the recommendations engine wakes up and reads from every signal source we have on you. That includes your prompt-level scan results, your content audit, your structured data analysis, your competitive share of voice, your co-mention patterns with competitors, and your AI bot crawl logs. It pulls candidates from all of those in parallel.
Each candidate carries a few important pieces of metadata. There is a recommendation type, a target page or query, an impact estimate in visibility points, and an effort estimate in hours. The engine takes every candidate, deduplicates them with a stable fingerprint so the same page does not generate the same suggestion twice, sorts by estimated impact, and writes the top results into your queue. You see suggestions ordered by impact level, with a hard cap of 20 active items at a time so the queue stays workable.
The impact estimate is calculated, not guessed. The formula multiplies a base point value for the recommendation type by the gap size, adds a small platform multiplier (a gap that affects four AI platforms scores higher than the same gap on one), and caps the total at a per-type ceiling. The result is a number you can sort by and a label you can scan for (high, medium, low).
The 11 signal types, in plain language
There are 11 recommendation types in the engine today, grouped into four broad categories.
Content moves. These are the recommendations that say "here is a query where your competitors get cited and you do not, write something about it." They come from the content gaps service and the topic authority service together, and they are the workhorses of the engine. They name the query, list which platforms are missing you, list which competitors are showing up instead, and give you a four-step plan to close the gap.
Structured data moves. These say "this page is missing FAQPage schema, Article schema, or HowTo schema, and here is the JSON-LD to paste in." The action plan often includes the generated JSON-LD as a copy-paste block, because there is no reason to make you write that twice. Adding structured data is one of the highest-leverage things you can do for AI visibility. A widely-cited Princeton study on Generative Engine Optimization found that combining structured citations, statistics, and source authority can lift citation rates in AI answers by up to 40%[^2]. BrightEdge research summarized in current schema-markup analyses puts the lift at around 2.5x for AI answer appearances on schema-complete pages[^3].
Competitive and positioning moves. This bucket includes co-mention recommendations (the engine notices when a competitor is co-cited with you in 70% or more of the prompts where you appear, and tells you to differentiate) and competitor intel recommendations (the engine notices when a competitor has more than a 20-point share of voice lead in a topic cluster, and tells you which keywords to attack). These come from your scan results and your share of voice snapshots, and they are how the tool stops being a passive monitor and starts being a competitive radar.
AI Traffic moves. The newest set, added with our AI Traffic feature. These look at the AI bot crawl logs and the AI referral traffic and surface things like "GPTBot crawled this page weeks ago and has not cited it yet," "your llms.txt discovery file is missing," or "ChatGPT is sending you visitors but this landing page is converting at a fraction of your site average." These recommendation types only fire on brands that have AI Traffic instrumented, but when they do, they tend to be some of the most concrete suggestions the engine produces.
For a primer on the underlying ideas these signals live in, our complete guide to generative engine optimization covers the optimization landscape in depth.
Walking through one recommendation
Here is the shape of what one looks like in the queue.
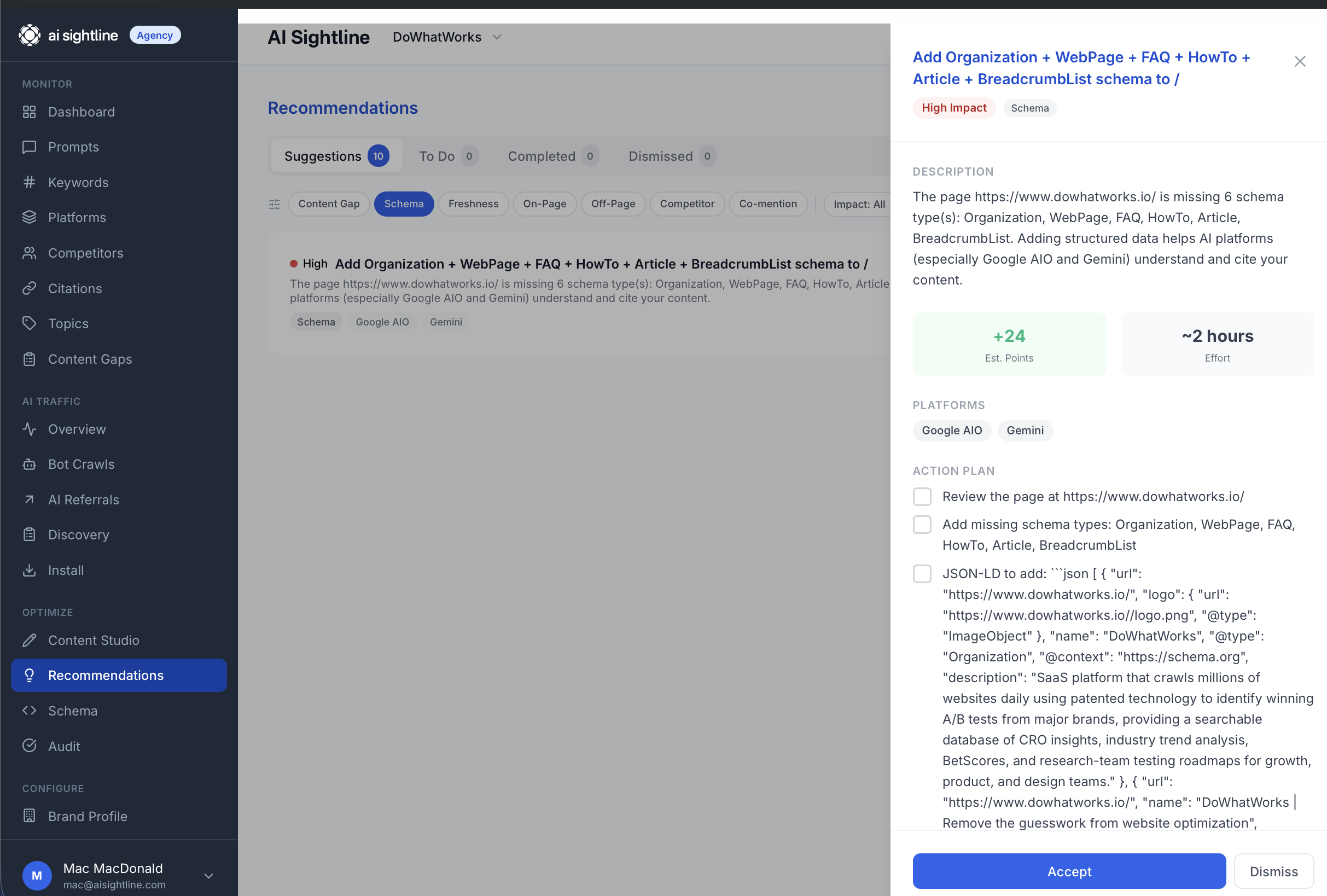
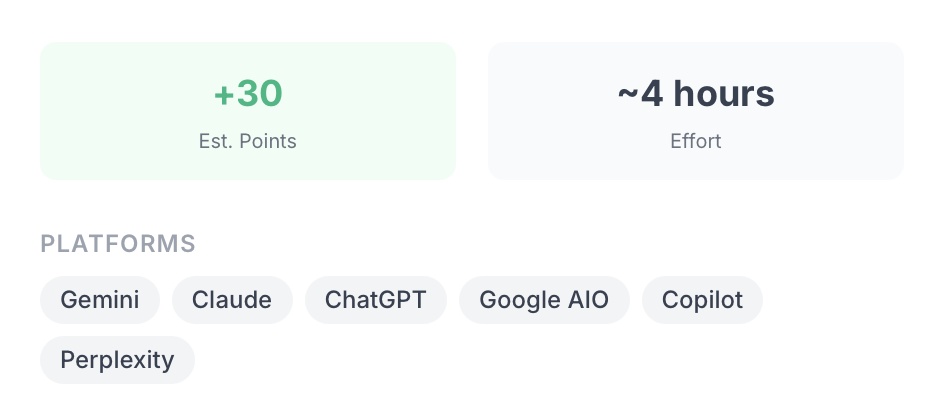
A schema recommendation might land with the title "Add FAQPage and Article schema to /pricing." The description tells you which schema types are missing and why it matters for AI citation. The action plan is four steps: review the page, add the listed schema types, paste in the generated JSON-LD (included as a code block in step three), and validate with Google's Rich Results test. Effort estimate: roughly two hours. Impact estimate: around 16 visibility points, labeled high.
You open it, you decide it is worth doing, you click accept. The recommendation moves from "suggestion" to "accepted." You work through the action plan over the next day. When you are done, you click complete. The moment you do, the engine snapshots your current composite visibility score as the "before" value on that recommendation.
Then you wait for the next scan cycle. Pro plans and above run daily, so for most paying customers this is the next morning. After the scan finalizes, the engine looks for completed recommendations from the last 14 days that do not yet have an "after" value, takes your new score, and writes both the "after" value and the difference (the actual points earned) onto the record.
That is the loop. Suggest, accept, complete, measure. The Impact Report at /portal/optimize/recommendations/impact shows you the cumulative score gain across everything you have shipped, which is a more useful number than "score went up this month" because it ties the gain to specific work you did.
How content generation fits in
The content gap recommendations are the most common type in most accounts, and they pair naturally with our Content Studio. The pattern looks like this. The engine surfaces a content gap recommendation: "you are invisible for 'AI visibility software for agencies' across ChatGPT, Perplexity, and Gemini, and here are the competitors winning it." That recommendation tells you what to write. Content Studio writes the first draft.
Content Studio takes the same query the recommendation flagged, pulls your brand description, and generates one of three deliverables: a content brief (an outline with target queries, suggested headings, and a structural plan), a full article, or an FAQ block ready to drop into the page. The output is intentionally tuned toward AI extraction. Short, declarative paragraphs. Self-contained answer blocks. Citations and statistics where they are warranted, because the same Princeton research that found structured data lifts citation rates also found that content with concrete statistics and authoritative sources gets cited at meaningfully higher rates.
The reason to pair the two is timing. The recommendation tells you a gap exists today, and Content Studio gives you a first draft of the page that closes it. You still edit, still add your own voice, still publish through your CMS. The time from "huh, we are missing this" to "draft is in the editor" drops from a half day to roughly fifteen minutes.
For more on how Google AI Overviews specifically pick up content, our piece on Google AI Overviews and what triggers them is a useful companion read.
Measuring real impact
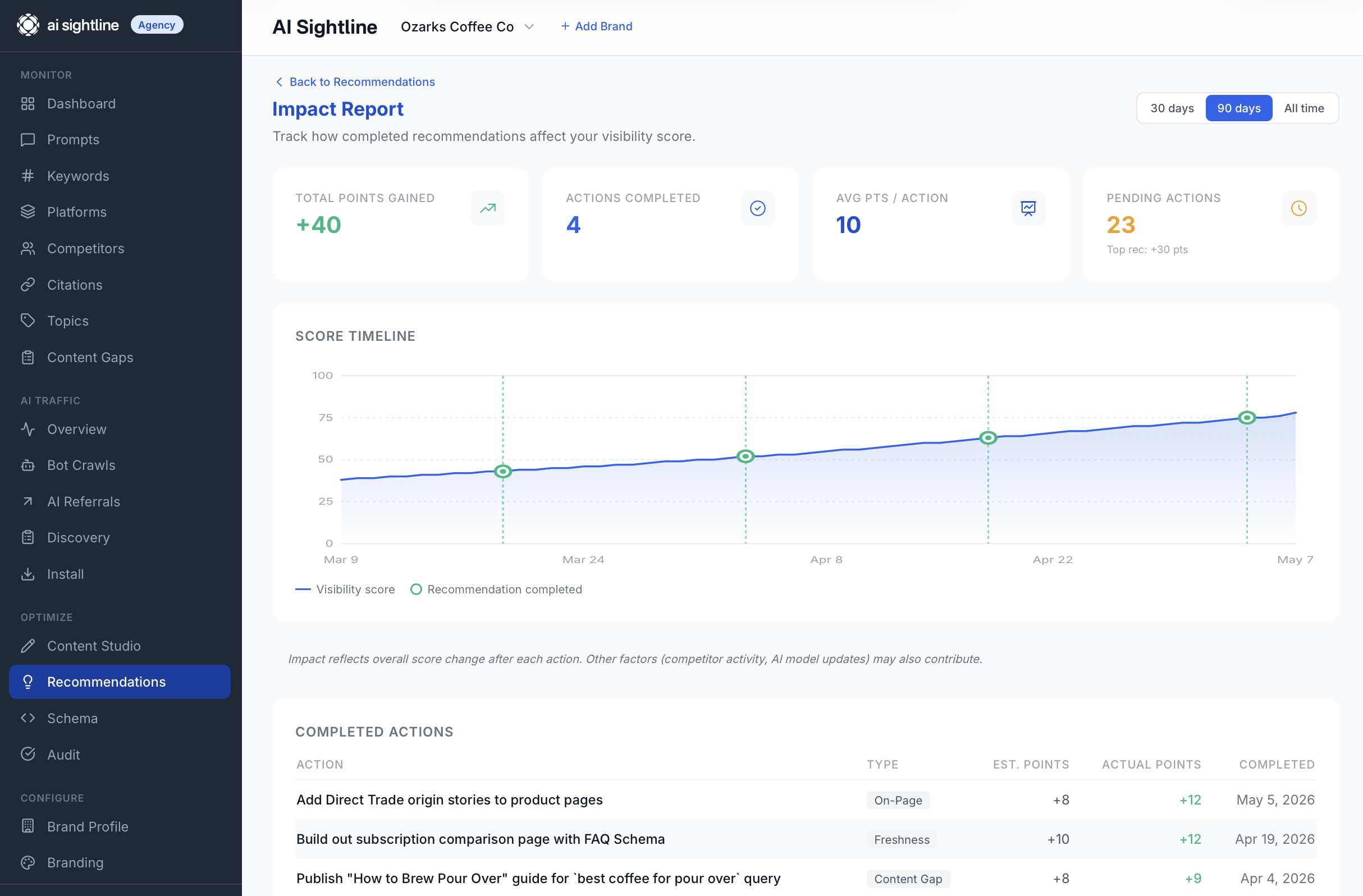
The reason the before-and-after snapshot exists is that the alternative (just watching "did my visibility score go up this month") is a noisy signal. Your score moves for a hundred reasons every week. Algorithms shift. Competitors publish. Your own scan coverage rotates across prompts. Attributing those changes to anything specific you did is hard.
Tying a snapshot to the moment you mark a recommendation complete cleans that up. You get a per-recommendation effect size, not a vague monthly trend. Over a quarter you build up a small portfolio of "we shipped this, it earned that," which is the kind of number that holds up in a meeting.
This matters more than it might sound, because AI search traffic, when it does start to arrive, behaves differently from regular organic traffic. A recent Pixis analysis and an Ahrefs analysis both found that AI referral visitors convert at roughly 4 to 5 times the rate of standard organic visitors, with B2B SaaS sitting at the higher end of that range[^4]. A small visibility gain can compound into a disproportionate revenue impact, which is exactly why a clean record of what worked is worth the small overhead of marking recommendations complete.
For the broader strategic difference between SEO and GEO, our GEO vs SEO breakdown lays out where the two practices converge and where they diverge.
What is included by tier
Suggestions ship on every plan. The monthly volumes and the depth of the impact tooling are what scale.
The Free plan includes 2 suggestions per month and one round of content generation, which is enough to see how the system works on a small brand footprint. Starter, at $29.95 per month, raises that to 10 suggestions and 3 content generations per month, with basic schema analysis. Pro, at $149.95 per month, is where most teams land: 75 suggestions per month, 25 content audit pages per month, 10 content generations per month, the full Content Studio, daily scans across five AI platforms, the full Impact Report, and topic authority clustering. Business at $289.95 per month raises those volumes to 300 suggestions, 100 audit pages, and 50 content generations per month for teams managing more brands or running heavier content programs. Agency at $549.95 per month lifts the ceiling again to 750 suggestions, 500 audit pages, and 200 content generations per month, with up to 50 brands under one account.
Multi-brand customers run all their brands under a single subscription with pooled quotas, so an agency on the Agency plan can split those 750 monthly suggestions across all 50 of its brands however the work demands.
In conclusion
The recommendations engine is the part of AI Sightline that takes everything we know about your visibility and turns it into a small, ranked, executable list. It pulls from 11 distinct signal sources, deduplicates them, scores them by estimated impact, and caps the queue at 20 active items so the work stays manageable. It pairs naturally with Content Studio for the content gap recommendations and with the Impact Report for the after-action measurement. The whole system is designed so that closing the loop (doing the work and measuring the result) is the default path, not the heroic one.
The Free plan is the simplest way to see the engine running against your own brand. Add a brand at aisightline.com, and after the first scan cycle your first set of suggestions will be waiting in the queue.
Sources:
[^1]: 5W Research, Overlap Between Top Google Rankings and AI-Cited Sources Has Collapsed From 70% to Under 20%, PRNewswire, 2026.
[^2]: Aggarwal et al., GEO: Generative Engine Optimization, Princeton University, 2023.
[^3]: BrightEdge research, summarized in Stackmatix, Structured Data for AI Search: Schema Markup Guide (2026).
[^4]: Pixis, Why AI Search Traffic Converts at 4-5x: What the Data Actually Shows, 2026.
Get your free AI visibility score.
See how ChatGPT, Claude, Perplexity, Gemini, Google AIO, and Copilot talk about your brand.
Start freeSolo founder building AI visibility monitoring. Ships weekly. No venture capital, a lot of opinions about where AI search is going.


