A growing list of AI visibility platforms claim to show you what your customers see when they ask ChatGPT, Perplexity, Gemini, or Copilot about your brand. Profound built an entire blog post around the phrase "seeing what customers see." Otterly markets "real consumer experience tracking." Several others run the same play.
It is a great pitch. It is also a fiction.
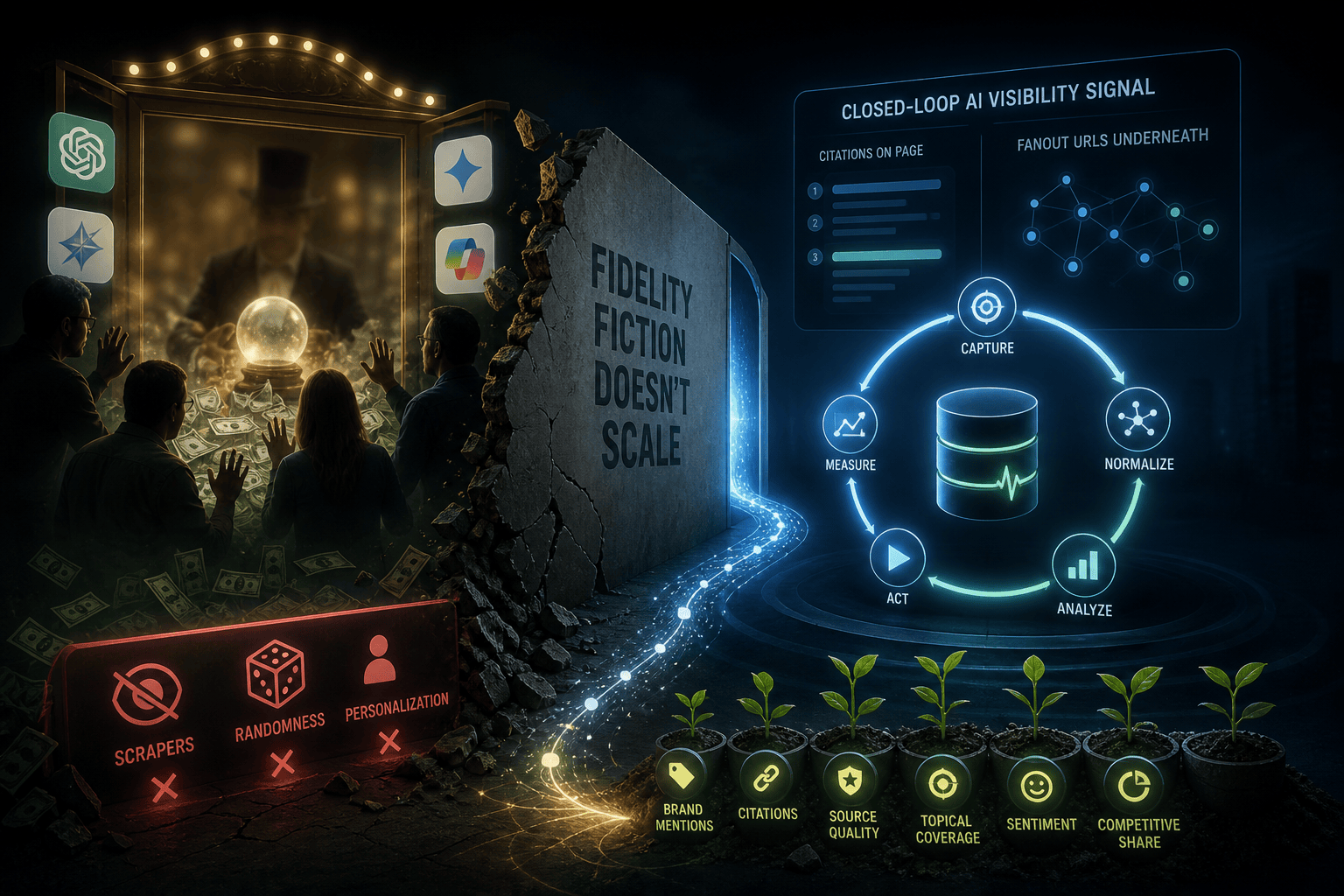
No monitoring tool, including ours, sees what your customers see. The math does not work. And once you understand why, you stop paying for fidelity stories and start paying for the thing that actually moves your AI search visibility: a live, grounded, closed-loop signal that captures both the citations on the page and the fanout URLs underneath them.
This post lays out the three tiers of AI visibility monitoring, the personalization stack that breaks every fidelity claim, the structural reason scrapers are now doubly out of luck on ChatGPT, and the technical approach that replaces fiction with feedback.
The phrase that sells nothing real
"Seeing what customers see" only makes sense in a world where every customer sees the same thing. That world does not exist for modern consumer AI products.
When two real users ask the same AI search engine the same question on the same day, they almost always get different answers. Not slightly different. Materially different in the brands cited, the URLs surfaced, the sentiment expressed, and the recommendations given. The variance is not a bug. It is the entire point of personalized retrieval-augmented systems.
Pretending otherwise is what lets vendors charge five-figure monthly retainers for what is actually a synthetic, single-IP, logged-out capture taken at one moment in time. It is useful data. It is not customer reality.
The three tiers of AI visibility monitoring
The market has settled into three meaningfully different approaches. Buyers should know which one their tool actually uses, because the difference shows up in the recommendations and the results.
Tier 3: API-only against stale models
Some tools call older language model endpoints with no retrieval enabled. The model returns what it learned during training, which is months or years out of date. New product launches do not show up. Recent reviews are invisible. PR crises that broke last week never reach the response.
Profound was right to call out this approach in their March 2025 post. It is genuinely useless for tracking AI visibility. If your monitoring tool cannot show you citations to live web sources for every response, it is probably running this way. Ask the vendor directly.
Tier 2: Capture from the consumer surface and call it customer reality
This is the approach Profound and several of their copycats build their pitch on. The implementation varies. Some vendors run automated browsers and scrape the rendered ChatGPT, Perplexity, or Copilot page. Others hit those platforms' APIs with browsing or web-search enabled. Others run a hybrid. The exact method matters less than the marketing claim layered on top of it.
The good news: this approach does see grounded retrieval. It is meaningfully better than Tier 3 because the consumer products invoke web search at query time, so fresh content shows up.
The bad news: the marketing claim that this equals customer reality is fiction once you understand what is actually happening on the platform side. We will get into the full personalization stack in a moment. The short version: a logged-out, no-memory, single-shot, US-based capture is not "what customers see." It is one synthetic baseline among hundreds of millions of personalized realities.
The expensive news: tools using this approach often charge thousands of dollars per month for what is, technically, a more honest Tier 1 capability dressed up as something it is not.
Tier 1: Live, grounded, closed-loop visibility intelligence
The honest version of AI visibility monitoring does not pretend to mirror personalized customer experiences. It does five things instead.
It queries the latest production models on every major AI platform with retrieval turned on, so every response is grounded in the live web index rather than stale training data. It captures the citations that appear in the rendered response. It captures the fanout URLs the AI pulled into its retrieval set during multi-step internal search, including URLs that did not make the final answer. It generates specific content recommendations tied to the gaps that data reveals. And it measures the lift those recommendations produce on the next scan cycle.
That last loop, which we call closed-loop visibility lift, is what separates monitoring from intelligence. More on that below. First, the personalization stack that breaks the Tier 2 fidelity claim.
The seven layers of personalization that no capture method can replicate
A real user's response is shaped by at least seven independent variables. Strip any one of them out and you no longer have customer reality. You have a baseline.
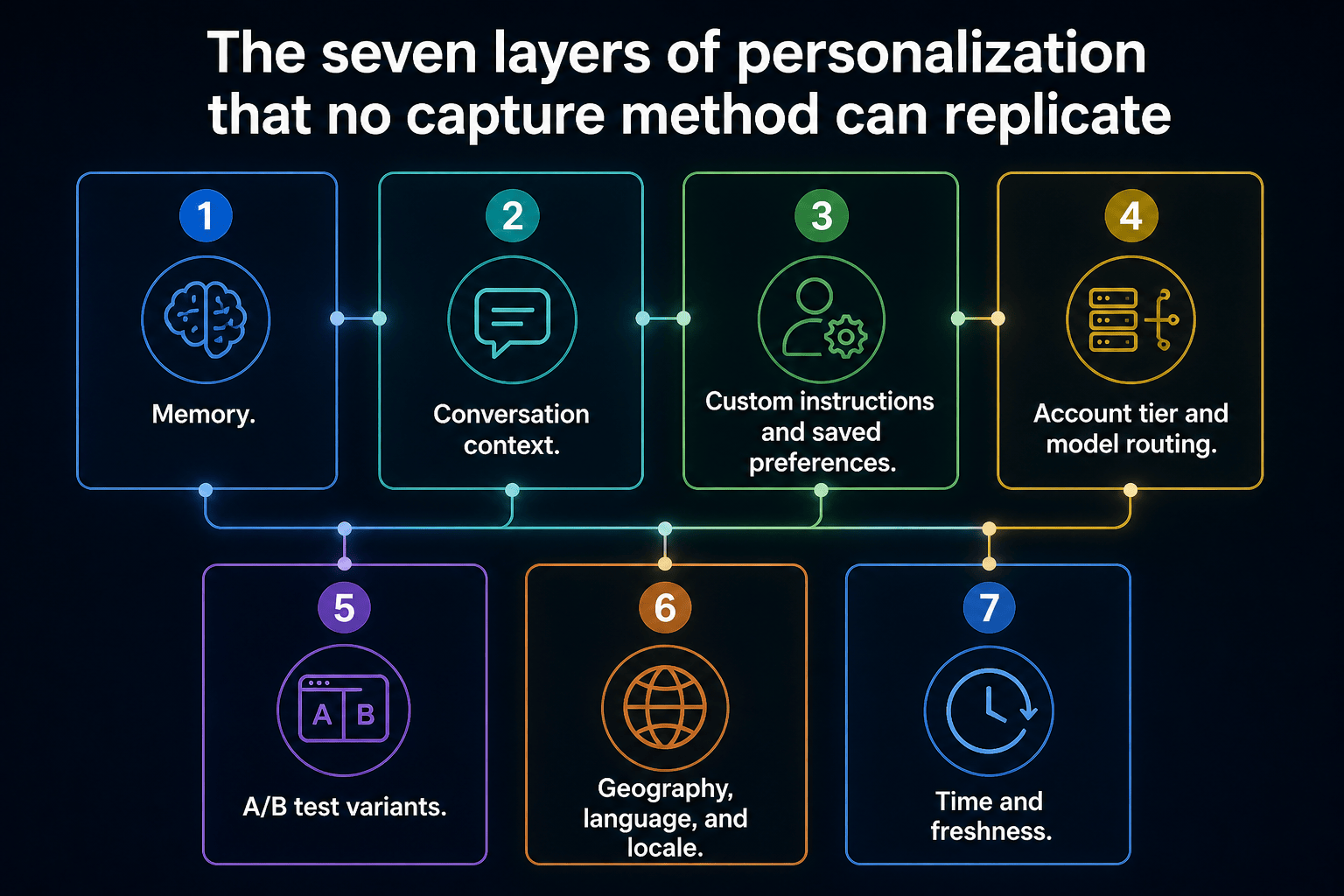
Memory. ChatGPT memory has been broadly deployed since 2024. The model literally remembers facts, preferences, and prior conversations and conditions answers on them. Perplexity has memory. Gemini personalizes from your Google account activity, including Search, Maps, YouTube, and Gmail when connected. Copilot pulls from Microsoft 365 context for logged-in users.
Conversation context. Real users do not ask one shot questions. They ask "best CRM" after twenty minutes of context about their fintech startup. Query number fifteen in a thread is not query number one in a fresh tab. Most consumer queries happen mid-conversation, and the surrounding turns dramatically reshape the answer.
Custom instructions and saved preferences. Users set persistent system prompts: "I am a developer, prefer technical depth," "give me Markdown only," "I am vegan." These change which brands get recommended, which products get filtered out, and how the answer is structured.
Account tier and model routing. Free users, Plus users, Pro users, and Enterprise users get different models, different rate limits, different retrieval depth, and different rerankers. A capture from one tier is not your customer base. Your customers are spread across all of them.
A/B test variants. OpenAI, Google, and Microsoft are constantly running silent experiments on prompt scaffolds, retrieval pipelines, rerank models, and citation formats. At any given moment, two users in the same city on the same plan asking the same query receive different answers because they are in different test buckets. You cannot capture your way out of this. The variance is engineered into the system.
Geography, language, and locale. Localized retrieval, regional compliance gating under the EU AI Act and DSA, language defaults, and in-country indexes all shift answers. A capture from a single datacenter IP in one region is not customer reality. It is what that one IP sees.
Time and freshness. Grounded retrieval re-indexes the live web continuously. The answer at 9am in New York differs from the answer at 5pm in Frankfurt because the news cycle, social conversations, and freshly indexed content shifted. Monitoring tools sample at fixed cadence. Customers query continuously across the day.
Multiply seven layers together and you do not have one customer experience. You have hundreds of millions of unique experiences, none of which any monitoring tool can reproduce. Anyone telling you otherwise is selling a story.
What capture actually delivers (the honest version)
A clean, logged-out, no-memory, single-shot, US-based session captures one specific thing: the answer a synthetic baseline user would receive at the moment of capture. It is a useful baseline. It is reproducible. It lets you track changes over time. It is not customer reality.
The closest analogy: measuring "the average driver's experience" by driving a brand new car off the lot in a closed test track. The data is real. The data is reproducible. The data is also not what any actual driver is experiencing on the road.
This is the part the market has been afraid to say out loud, because saying it out loud forces vendors to defend a smaller, more honest claim. Smaller honest claims are harder to charge five-figure retainers for.
The dish and the ingredients: why fanout URLs matter
Here is the technical detail that most AI visibility content glosses over, and the place where capture-only tools fall a layer short.
When a user submits a single prompt to a modern AI search engine, the system does not run one search. It internally generates multiple subqueries, sometimes five, sometimes more than ten, then pulls URLs for each subquery, then synthesizes one answer from the combined retrieval set. Google has publicly documented this for AI Overviews. Perplexity runs explicit multi-stage retrieval. ChatGPT browsing iteratively refines its searches mid-response.
The final response is the dish. The fanout URLs are the ingredients.
If a tool only shows you the citations that appear in the visible answer, it is showing you the plate. The retrieval set behind the answer is much larger and much more diagnostic. Pages that consistently show up in fanout but never make the final citation list are competing for inclusion and losing the synthesis fight. That is the most actionable visibility data in the entire category, and it is invisible to tools that only capture rendered citations.
A page that never appears in fanout means the AI does not consider you relevant for the query at all. The fix is broad topical authority work. A page that appears in fanout but loses the synthesis fight means you are relevant but losing on freshness, structure, schema, or rerank signal. The fix is targeted page-level optimization. Two completely different diagnoses, two completely different content strategies, both invisible if your monitoring tool only captures the visible citations.
We capture both layers. The dish and the ingredients.
The GPT-5.5 wrinkle: surface scrapers are doubly out of luck
Here is the part most AI visibility vendors would rather buyers not inspect too closely. The GPT-5.5 wrinkle: surface scrapers are out of luck
ChatGPT’s consumer UI shows the answer, visible citations, and in some cases a Sources panel. It does not expose the full retrieval process as a structured data product. That matters because the cited URLs are only the visible tip of the retrieval layer. OpenAI’s own API documentation distinguishes between inline citations and the broader sources field, which can include the complete list of URLs the model consulted when forming the answer.
In plain English: the UI gives you the dish. The API can give you more of the ingredients, when the platform exposes them.
That creates a real structural gap for monitoring vendors. If a tool claims to track ChatGPT fanout by scraping the rendered consumer page, it can capture only what ChatGPT renders: the answer, visible citations, and visible source links. It cannot recover retrieval metadata that was never placed in the DOM.
API-based monitoring has a better shot because it can request structured web-search metadata where the platform supports it. Surface scraping cannot reconstruct hidden retrieval state after the fact.
So if a vendor pitches “fanout tracking” for ChatGPT, the buyer should ask one blunt question: are you using platform-level retrieval metadata, or are you scraping the consumer UI? If the answer is UI scraping, they are not tracking full fanout. They are tracking visible citations and calling it fanout.
RAG, grounding, browsing, web search: stop letting vendors gatekeep basic concepts
While we are clearing up category jargon, one more thing.
"Retrieval-augmented generation," or RAG, is the academic term for a technique introduced in a 2020 Meta research paper. It describes any system that retrieves external documents and injects them into a language model's context window before generating a response.
Every consumer AI search product implements this same loop. The vendors all rebrand it. Google calls it grounding. OpenAI calls it browsing or web search. Perplexity just calls it search. Microsoft calls it Bing-grounded responses. Anthropic calls it the web search tool.
These are the same concept wearing different jerseys. When a vendor markets "RAG-based monitoring" as if it were a proprietary architectural advantage, they are using the academic term to make a basic capability sound like a moat. It is not. Any tool that hits a consumer AI surface, or hits an API with retrieval enabled, gets RAG-style grounded responses. The interesting question is not whether retrieval is happening. It is what is being captured beyond the surface citation, and whether the platform still exposes that data at all.
The closed-loop visibility lift cycle
Capturing live grounded data is necessary. It is not sufficient. The next step, and the place AI Sightline is built differently than every observation-only competitor, is closing the loop between what you observe and what you ship.
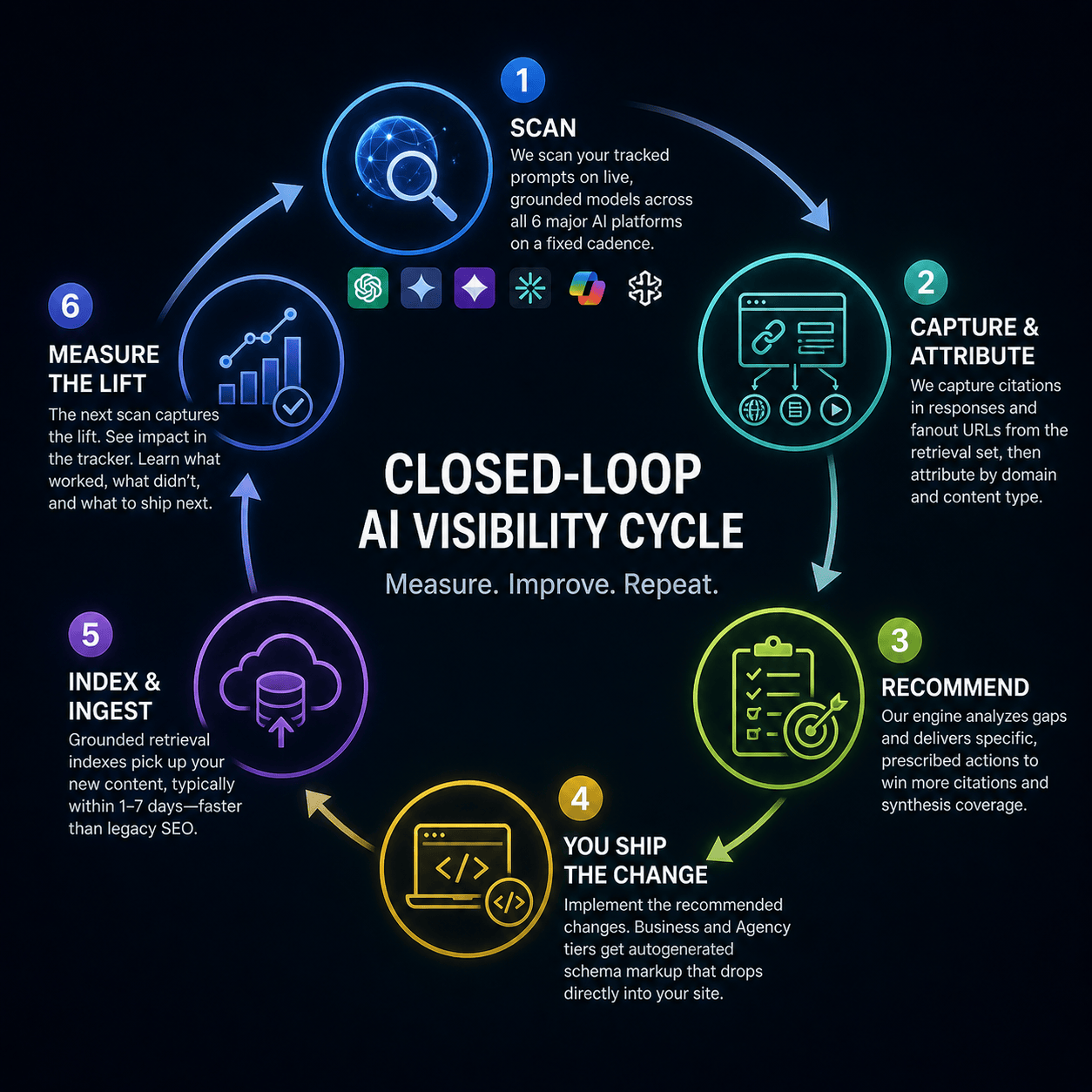
Here is the cycle.
-
We scan your tracked prompts on live grounded models across all six major AI platforms on a fixed cadence, daily on Pro and above, every three days on Starter, weekly on Free.
-
We capture the citations that appear in each response and the fanout URLs the AI pulled into its retrieval set, then attribute everything to specific competing domains and content types.
-
Our recommendations engine analyzes the gaps and produces specific, prescribed actions: publish an FAQ schema block on a particular page, add a comparison table to a target URL, fix a citation gap on a topic where you appear in fanout but lose the synthesis fight, claim authority on a topic where you do not appear at all.
-
You ship the change. Business and Agency tiers get autogenerated schema markup that drops directly into your site.
-
The grounded retrieval indexes pick up your new content, typically within one to seven days, which is dramatically faster than legacy organic SEO because AI retrieval re-indexes on a much shorter cycle than Google's main web index.
-
The next scan captures the lift. You see the impact in the recommendation tracker. You learn what worked, what did not, and what to ship next.
That feedback loop, which moves on a multi-day rather than multi-month timeline, is the difference between knowing your AI visibility and changing it. Observation-only tools tell you the score. Closed-loop tools change the score.
What honest AI visibility monitoring actually claims
Here is the claim AI Sightline makes, and the claim any honest tool in this category should make.
We do not see what your customers see. Personalized memory, account-tier routing, A/B test variants, and per-user retrieval context make that mathematically impossible for any tool, at any price, anywhere in the market.
What we give you is something better than a fidelity fiction. We give you a live, grounded, closed-loop visibility signal that goes deeper than the visible answer. We query the latest production models on every major AI platform with retrieval turned on. We capture both the citations in the final response and the fanout URLs the AI pulled during its internal multi-step search, the ingredients behind every answer. We recommend specific content fixes tied to the gaps that data reveals. We measure the lift within days.
You are not paying for a fidelity illusion. You are paying for the only feedback loop in the category that maps the full retrieval kitchen, not just the plated dish.
The practical buyer's checklist
If you are evaluating AI visibility platforms, these are the questions that cut through marketing language fastest.
-
Are you calling APIs with retrieval enabled, capturing from consumer interfaces, or both? What is the technical reason for the choice, and how does that choice survive the GPT-5.5 fanout-removal change?
-
Do you capture the fanout URLs the AI pulled into its retrieval set, or only the citations that appear in the rendered response? Can you show me the fanout data in your dashboard right now?
-
What is your scan cadence on the tier I am buying? How quickly does new content I publish show up in your impact data?
-
Do you generate specific content recommendations tied to the gaps you observe, and do you measure whether those recommendations produced visibility lift?
-
Are you claiming to mirror customer experience? If so, what is your answer to memory, A/B variants, account-tier routing, and geography?
A vendor who answers question five with anything other than "we do not, and here is what we do instead" is selling a story. A vendor who cannot answer question two is operating one technical layer above the one that matters.
Where AI Sightline lands
We capture both layers. We close the loop. We charge $29.95 a month at the entry tier and $549.95 at the top, which is materially below every observation-only competitor at comparable depth, and we do not hide the fact that no monitoring tool sees what customers see, including ours.
If that level of honesty about what AI visibility monitoring can and cannot deliver is the kind of partner you want, start with the Free tier and run a real comparison against whatever else you are evaluating. The fanout data alone will tell you which tools are operating at the surface and which ones are looking underneath.
The fidelity fiction era of AI visibility monitoring is ending. The closed-loop era is what comes next.
What is fidelity in AI visibility monitoring?
Fidelity is how closely a monitoring tool reproduces the AI response a real user would see at the same moment. Higher fidelity means querying the live model, in the right region, with grounding or web search turned on, and parsing the actual cited URLs. Lower fidelity tools rely on cached or simulated responses and miss real-time changes.
Why do different AI visibility tools report different scores?
Three reasons: which prompts each tool scans, how often it scans them, and whether it queries the live model versus a snapshot. Two tools using different prompt sets will never agree on share of voice, even if both are technically correct. Pick a tool with transparent methodology and stick with it for trend continuity.
Is true real-time AI tracking possible?
Not at scale. Live model latency, rate limits, and cost make second-by-second tracking impractical. Daily cycles with sampled prompts are the realistic ceiling today, which is what AI Sightline runs on Pro and above. Anything claiming true real-time is almost certainly aggregating cached responses.
Which fidelity level should I trust?
Trust tools that name the exact model version, scan frequency, prompt count, and grounding mode they use. Anything that hides those numbers is selling a black box. Ask for a sample scan report before you buy.
Get your free AI visibility score.
See how ChatGPT, Claude, Perplexity, Gemini, Google AIO, and Copilot talk about your brand.
Start freeSolo founder building AI visibility monitoring. Ships weekly. No venture capital, a lot of opinions about where AI search is going.


